Important, commonly-used datasets in high quality, easy-to-use & open form as data packages
Showing posts with label Datasets for Deep Learning. Show all posts
Showing posts with label Datasets for Deep Learning. Show all posts
Thursday, May 24, 2018
Wednesday, May 23, 2018
Best Public Datasets for Machine Learning and Data Science
While shaping the idea of your data science project, you probably dreamed of writing variants of algorithms, estimating model performance on training data, and discussing prediction results with colleagues . . . But before you live the dream, you not only have to get the right data, you also must check if it’s labeled according to your task. Even if you don’t need to collect specific data, you can spend a good chunk of time looking for a dataset that will work best for the project.
Thousands of public datasets on different topics — from top fitness trends and beer recipes to pesticide poisoning rates — are available online. To spend less time on the search for the right dataset, you must know where to look for it.
This article is aimed at helping you find the best publicly available dataset for your machine learning project. We’ve grouped the article sections according to dataset sources, types, and a number of topics:
- Catalogs of data portals and aggregators
- Government and official data
- Scientific research data
- Verified datasets from data science communities
- Political and social datasets from media outlets
- Finance and economic data
- Healthcare data
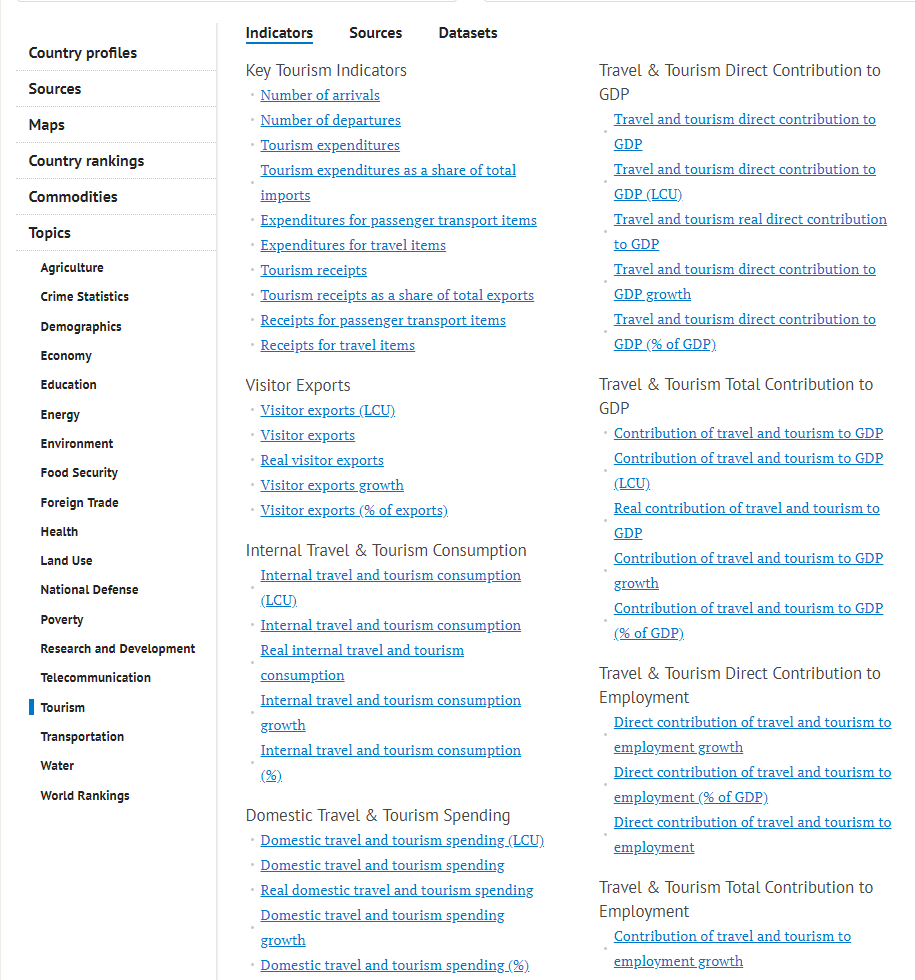
- Travel and transportation data
- Other sources
Catalogs of data portals and aggregators
While you can find separate portals that collect datasets on various topics, there are large dataset aggregators and catalogs that mainly do two things:
1. Provide links to other specific data portals. The examples of such catalogs are DataPortals and OpenDataSoft described below. The service doesn’t directly provide access to data. Instead, it allows users to browse existing portals with datasets on the map and then use those portals to drill down to the desirable datasets.
2. Aggregate datasets from various providers. This allows users to find health, population, energy, education, and many more datasets from open providers in one place — convenient.
Let’s have a look at the most popular representatives of this group.
DataPortals: meta-database with 524 data portals
This website’s domain name says it all. DataPortals has links to 524 data portals around the globe.
The homepage contains a zoomable map, so specialists can easily find their portal of interest. They can also use the search panel or go to a page where data portals are listed and described.
Users can contribute to the meta-database, whether a contribution entails adding a new feature and data portal, reporting a bug on GitHub, or joining the project team as an editor.
OpenDataSoft: a map with more than 2600 data portals
The open data portals register by OpenDataSoft is impressive — the company team has gathered more than 2600 of them. The list looks like an interactive map, similar to the one on DataPortlas. Data portals are also grouped by countries, so users can choose between two search options.
OpenDataSoft provides data management services by building data portals. With its platform, clients publish, maintain, process, and analyze their data.
Knoema: home to nearly 2.5-billion time series data of 1000 topics from more than 1000 sources
This search engine was specifically designed for numeric data with limited metadata — the type of data specialists need for their machine learning projects. Knoema has the biggest collection of publicly available data and statistics on the web, its representatives state. Users have access to nearly 2.5-billion time series data of 1000 topics obtained from more than 1000 sources, the information being updated daily.
Knoema provides efficient data exploration tools with datasets clustered by sources and topics. The search by topic can be narrowed down with Sources and Indicators filters. Datasets are also listed in alphabetical order.
Knoema’s data explorer
Data scientists can study data online in tables and charts or downloaded as an Excel file, for example. However, the export isn’t free and requires a premium account.
Government and official data
Data.gov: 237,545 sets of the US open government data
Searching for the public dataset on data.gov, “the home of the US Government’s open data,” is fast and simple. Users are free to choose the appropriate dataset among more than 237,545 related to 14 topics. When looking for a dataset of a specific domain, users can apply extra filters like topic category, location, tags, file format, organizations and their types, and publishers.
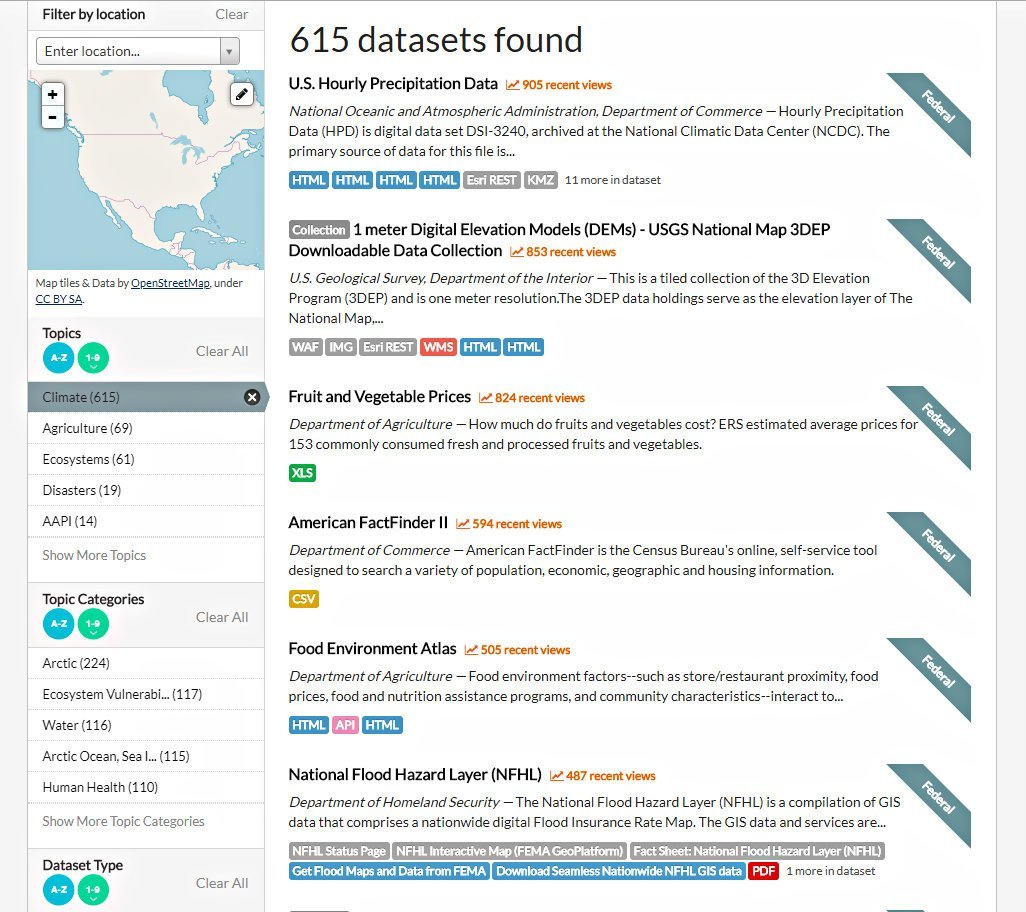
Various filters are available on data.gov
Eurostat: open data from the EU statistical office
The statistics office of the EU provides high-quality stats about numerous industries and areas of life. Datasets are open and free of charge, so everyone can study them online via data explorer or downloaded in TSV format.
The data navigation tree helps users find the way and understand data hierarchy. Databases and tables are grouped by themes, and some have metadata. There are also tables on EU policies, the ones grouped in cross-cutting themes. New and recently updated items are located in the corresponding folders.
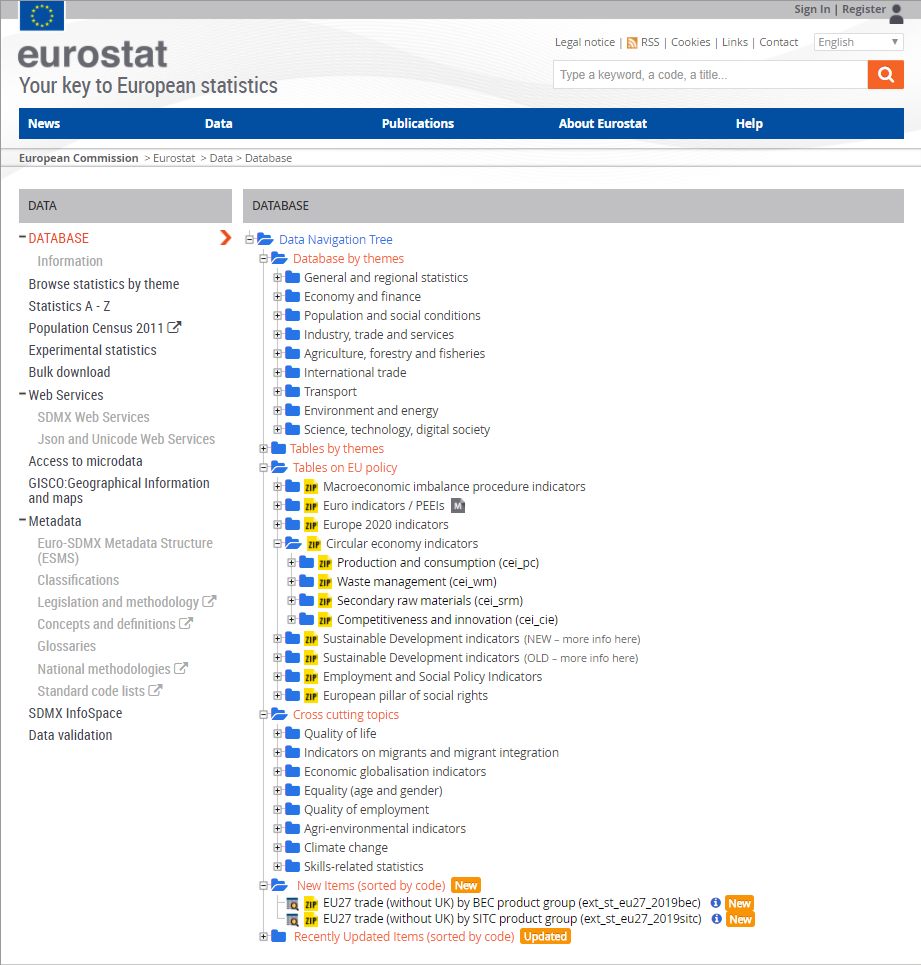
Data navigation tree of Eurostat database
If you want to get more data by state institutions, agencies, and bodies, you can surf such websites as the UK’s Office for National Statistics and Data.Gov.UK, European Data Portal, EU Open Data Portal, and OpenDataNI. Data portals of the Australian Bureau of Statistics, the Government of Canada, and the Queensland Government are also rich in open source datasets. Search engines at these websites are similar: Users can browse datasets by topics, and use filters and tags to narrow down the search.
Scientific research data
Datasets that you can find within this source category can partly intersect with government and social data described above. However, here we focused mostly on science-related portals and datasets.
Re3data: 2000 research data repositories with flexible search
Those looking for research data may find this source useful. Re3Data contains information on more than 2,000 data repositories. The catalog developers paid attention to its usability. It allows for searching data repositories by subject, content type, country of origin, and “any combination of 41 different attributes.” Users can choose between graphical and text forms of subject search. Every repository is marked with icons providing a short description of its characteristics and explaining terms of access and use.

Re3data provides two options of subject search
Research Pipeline: Wiki pages with datasets and other data science-related content
Research Pipeline is a Wikipedia-style website. If we were to describe this resource with a single phrase, it could be “everything in one place.” Users can look for free datasets, data processing software, data science-related content sources, or statistical organizations on its numerous Wiki pages. The data sources are grouped by topics and can also be reached through a search panel. Website creator Lyndie Chiou welcomes users to upload datasets and leave comments on the blog.
FAIRsharing: “resource on data and metadata standards, inter-related to databases and data policies”
FAIRsharing is another place to hunt for open research data. With 1058 databases listed on the source, specialists have a big choice. Users can search for data among catalogs of databases and data use policies, as well as collections of standards and/or databases grouped by similarities.
Users can also specify the search by clicking on checkboxes with domains, taxonomies, countries of data origin, and the organizations that created it. To speed up the process, a user can select a record type.
Verified datasets from data science communities
A really useful way to look for machine learning datasets is to apply to sources that data scientists suggest themselves. These datasets weren’t necessarily gathered by machine learning specialists, but they gained wide popularity due to their machine learning-friendly nature. Usually, data science communities share their favorite public datasets via popular engineering and data science platforms like Kaggle and GitHub.
DataHub: high-quality datasets shared by data scientists for data scientists
DataHub is not only a data management and automation platform but also a community for data scientists. The project founders created the Awesome section with high-quality public datasets on various topics and dataset collections. Machine learning datasets, datasets about climate change, property prices, armed conflicts, well-being in the US, even football — users have plenty of options to choose from. Besides linking datasets by other providers, the DataHub team made 333 datasets available for a download on the website.
UCI Machine Learning Repository: one of the oldest sources with 427 datasets
It’s one of the oldest collections of databases, domain theories, and test data generators on the Internet. The website (current version developed in 2007) contains 427 datasets, the oldest dated 1987 — the year when machine learning practitioner David Aha with his graduate students created the repository as an FTP archive.
UCI allows for filtering datasets by the type of machine learning task, number of attributes and their types, number of instances, data type (i.e. time-series, multivariate, text), research area, and format type (matrix and non-matrix).
Most of the datasets — clean enough not to require additional preprocessing — can be used for model training right after the download. What’s also great about UCI repository is that users don’t need to register prior upload.
data.world: open data community
data.world is the platform where data scientists can upload their data to collaborate with colleagues and other members, and search for data added by other community members (filters are also available.)
data.world offers tools simplifying data processing and analysis. Users can write SQL and SPARQL queries to explore numerous files at once and join multiple datasets. The platform also provides SDKs for R and Python to make it easier to upload, export, and work with data.
GitHub: a list of awesome datasets made by the software development community
It would be surprising if GitHub, a large community for software developers, didn’t have a page dedicated to datasets. Its Awesome Public Datasets list contains sources with datasets of 30 topics. Although most of the datasets won’t cost you a dime, be ready to pay for some of them. As contributors have to comply with format guidelines for the data they add to the Awesome list, its high quality and uniformity are guaranteed.
Kaggle datasets: 13,321 themed datasets on “Facebook for data people”
Kaggle, a place to go for data scientists who want to refine their knowledge and maybe participate in machine learning competitions, also has a dataset collection. Registered users can choose among 13,321 high-quality themed datasets.
Search box with filters (size, file types, licenses, tags) make it easy to find needed datasets. Another nifty feature — users can bookmark and preview the ones they liked.
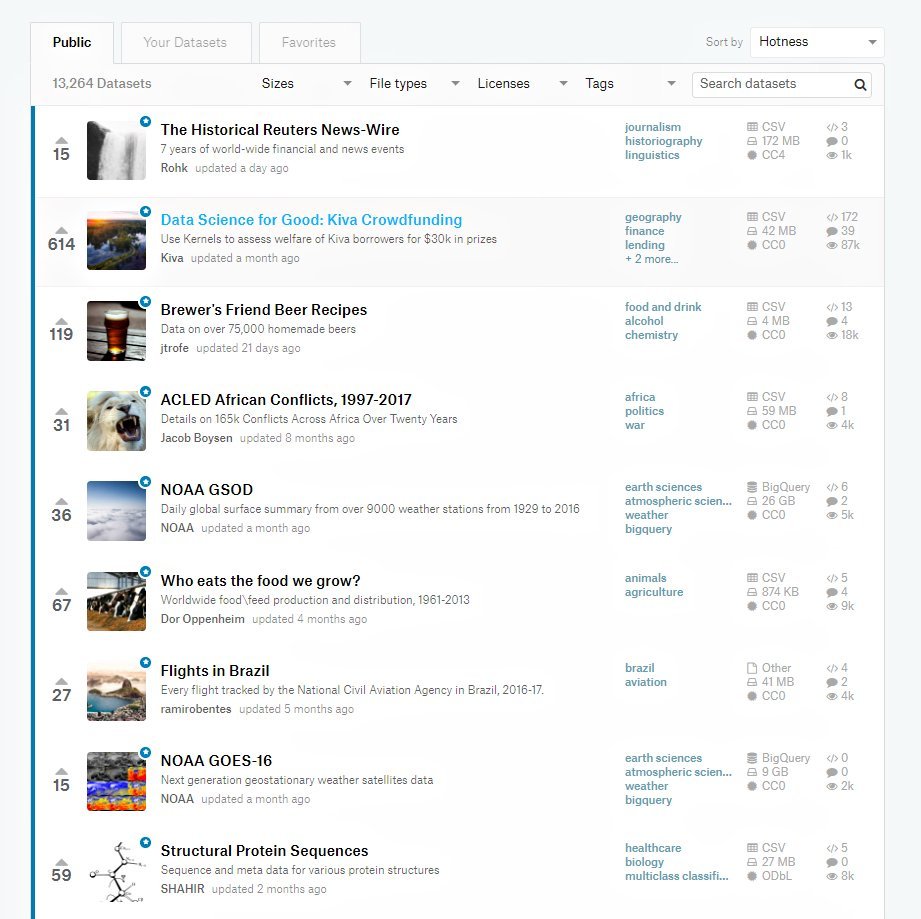
Searching for datasets on Kaggle is simple
When it comes to working with data, there are two options. Users can download datasets or analyze them in Kaggle Kernels — a free platform that allows for running Jupyter notebooks in a browser — and share the results with the community.
The Kaggle team welcomes everyone to contribute to the collection by publishing their datasets.
KDnuggets: a comprehensive list of data repositories on a famous data science website
A trusted site in scientific and business communities, KDnuggets, maintains a list of links to numerous data repositories with their brief descriptions. Data from international government agencies, exchanges, and research centers, data published by users on data science community sites — this collection has it all.
Reddit: datasets and requests of data on a dedicated discussion board
Reddit is a social news site with user-contributed content and discussion boards called subreddits. These boards are organized around specific subjects. Their members communicate with each other by sharing content related to their common interests, answering questions, and leaving feedback.
Browsing Datasets subreddit is like rummaging through a treasure chest because you never know what unique dataset you may come across.
Datasets subreddit members write requests about datasets they are looking for, recommend sources of qualitative datasets, or publish the data they collected. All requests and shared datasets are filtered as hot, new, rising, and top. There is also a wiki section and a search bar.
Political and social datasets from media outlets
Media outlets generally gather a lot of social and political data for their work. Sometimes they share it with the public. We suggest looking at these two companies first.
BuzzFeed: datasets and related content by a media company
BuzzFeed media company shares public data, analytic code, libraries, and tools journalists used in their investigative articles. They advise users to read the pieces before exploring the data to understand the findings better. Datasets are available on GitHub.
FiveThirtyEight: datasets from data-driven pieces
Journalists from FiveThirtyEight, famous for its sports pieces as well as news on politics, economics, and other spheres of life, also publish data and code they gathered while they work. Like BuzzFeed, FiveThirtyEight chose GitHub as a platform for dataset sharing.
Finance and economic data
Quandl: Alternative Financial and Economic Data
Quandl is a source of financial and economic data. The main feature of this platform is that it also provides alternative or untapped data from “non-traditional publishers” that has “never been exposed to Wall Street.” Acquiring such data has become possible thanks to digitalization. Alternative data is generated from IoT. Analysis of transactional data can give valuable insights into consumer behavior.
Clients can filter datasets by type, region, publisher, accessibility, and asset class.
Quandl shares some free data, but most of it comes at a price. Registered users can choose a format for data they get. They can access data via API and the web interface.
International Monetary Fund and The World Bank: International Economy Stats
The International Monetary Fund (IMF) and The World Bank share insights on the international economy. On the IMF website, datasets are listed alphabetically and classified by topics. The World Bank users can narrow down their search by applying such filters as license, data type, country, supported language, frequency of publication, and rating.
Healthcare data
World Health Organization: Global Health Records from 194 Countries
The World Health Organization (WHO) collects and shares data on global health for its 194-member countries under the Global Health Observatory (GHO) initiative.
Source users have options to browse for data by theme, category, indicator (i.e. existence of a national child-restraint law (Road Safety)), and by country. The metadata section allows for learning how data is organized. These healthcare datasets are available online or can be downloaded in CSV, HTML, Excel, JSON, and XML formats.
The Center for Disease Control (CDC): Searching for data is easy with an online database
The CDC is a rich source of US health-related data. It maintains Wide-ranging OnLine Data for Epidemiologic Research (WONDER) — a web application system aimed at sharing healthcare information with a general audience and medical professionals.
With CDC WONDER, users access public data hosted by different state sources, sorted alphabetically and by topic. Data can be used in desktop applications and is ready for download in CSV and Excel formats.
Medicare: data from the US health insurance program
Medicare is another website with healthcare data. It hosts 143 datasets focused on a comparison of services provided by its health institutions.
Travel and transportation data
National Travel and Tourism Office: overview of the US travel landscape
The website of the US National Travel and Tourism Office is a trusted source of travel data.
It runs several statistical programs aimed at snapping the big picture of US tourism industry. For example, the office provides the latest statistics on inbound and outbound travel, cities and states visited by overseas travelers, and so on. Users can save datasets as Excel and PDF files.
Federal Highway Administration: US road transportation data
The Federal Highway Administration of the US Department of Transportation researches the nation’s travel preferences under the National Household Travel Survey (NHTS) initiative. Received insights show, for example, what vehicles Americans use when traveling, the correlation between family income and a number of vehicle trips, as well as trip length, etc.
Survey data is available for online exploration and for downloading as CSV, SAS Transport files. Users can also work with it in dBase, SPSS, and SAS Windows binary applications.
Other sources
Amazon Web Services: free public datasets and paid machine learning tools
Amazon hosts large public datasets on its AWS platform. Specialists can practice their skills on various data, for example financial, statistical, geospatial, and environmental.
Registered users can access and download data for free. However, AWS provides cloud-based tools for data analysis and processing (Amazon EC2, Amazon EMR, Amazon Athena, and AWS Lambda). Those who prefer to analyze datasets with these tools online are charged for the computational power and storage they used.
Google Public datasets: data analysis with the BiGQuery tool in the cloud
Google also shares open source datasets for data science enthusiasts. Datasets are stored in its cloud hosting service, Google Cloud Platform (GCP) and can be examined with the BiGQuery tool. To start working with datasets, users must register a GCP account and create a project. While Google maintains storage of data and gives access to it, users pay for the queries they perform on it for analysis. The first terabyte of processed data per month is free, which sounds inspirational.
Cloud provider Microsoft Azure has a list of public datasets adapted for testing and prototyping. As it provides descriptions and groups data by general topics, the search won’t take much time.
Advice on the dataset choice
As so many owners share their datasets on the web, you may wonder yourself how to start your search or struggle making a good dataset choice.
When looking for specific data, first browse catalogs of data portals. Then decide what continent and country information must come from. Finally, explore data portals of that geographic area to pinpoint the right dataset.
You can speed up the search by surfing websites of organizations and companies that focus on researching a certain industry. If you’re interested in governmental and official data, you can find it on numerous sources we mentioned in that section. Besides that, data science communities are good sources of qualitative user-contributed datasets and data collections from different publishers.
It’s important to consider the overall quality of published content and make extra time for dataset preparation if needed. Sources like data.gov, data.world, and Reddit contain datasets from multiple publishers, and they may lack citation and be collected according to different format rules.
At the same time, data scientists note that most of the datasets at UCI, Kaggle, and Quandl are clean.
Top Open Datasets for Deep Learning
Introduction
The key to getting better at deep learning (or most fields in life) is practice. Practice on a variety of problems – from image processing to speech recognition. Each of these problem has it’s own unique nuance and approach.
But where can you get this data? A lot of research papers you see these days use proprietary datasets that are usually not released to the general public. This becomes a problem, if you want to learn and apply your newly acquired skills.
If you have faced this problem, we have a solution for you. We have curated a list of openly available datasets for your perusal.
In this article, we have listed a collection of high quality datasets that every deep learning enthusiast should work on to apply and improve their skillset. Working on these datasets will make you a better data scientist and the amount of learning you will have will be invaluable in your career. We have also included papers with state-of-the-art (SOTA) results for you to go through and improve your models.
How to use these datasets?
First things first – these datasets are huge in size! So make sure you have a fast internet connection with no / very high limit on the amount of data you can download.
There are numerous ways how you can use these datasets. You can use them to apply various Deep Learning techniques. You can use them to hone your skills, understand how to identify and structure each problem, think of unique use cases and publish your findings for everyone to see!
The datasets are divided into three categories – Image Processing, Natural Language Processing, and Audio/Speech Processing.
Let’s dive into it!
Image Datasets
MNIST

MNIST is one of the most popular deep learning datasets out there. It’s a dataset of handwritten digits and contains a training set of 60,000 examples and a test set of 10,000 examples. It’s a good database for trying learning techniques and deep recognition patterns on real-world data while spending minimum time and effort in data preprocessing.
Size: ~50 MB
Number of Records: 70,000 images in 10 classes
MS-COCO

COCO is a large-scale and rich for object detection, segmentation and captioning dataset. It has several features:
- Object segmentation
- Recognition in context
- Superpixel stuff segmentation
- 330K images (>200K labeled)
- 1.5 million object instances
- 80 object categories
- 91 stuff categories
- 5 captions per image
- 250,000 people with keypoints
Size: ~25 GB (Compressed)
Number of Records: 330K images, 80 object categories, 5 captions per image, 250,000 people with key points
SOTA : Mask R-CNN
ImageNet

ImageNet is a dataset of images that are organized according to the WordNet hierarchy. WordNet contains approximately 100,000 phrases and ImageNet has provided around 1000 images on average to illustrate each phrase.
Size: ~150GB
Number of Records: Total number of images: ~1,500,000; each with multiple bounding boxes and respective class labels
Open Images Dataset

Open Images is a dataset of almost 9 million URLs for images. These images have been annotated with image-level labels bounding boxes spanning thousands of classes. The dataset contains a training set of 9,011,219 images, a validation set of 41,260 images and a test set of 125,436 images.
Size: 500 GB (Compressed)
Number of Records: 9,011,219 images with more than 5k labels
SOTA : Resnet 101 image classification model (trained on V2 data): Model checkpoint, Checkpoint readme, Inference code.
VisualQA

VQA is a dataset containing open-ended questions about images. These questions require an understanding of vision and language. Some of the interesting features of this dataset are:
- 265,016 images (COCO and abstract scenes)
- At least 3 questions (5.4 questions on average) per image
- 10 ground truth answers per question
- 3 plausible (but likely incorrect) answers per question
- Automatic evaluation metric
Size: 25 GB (Compressed)
Number of Records: 265,016 images, at least 3 questions per image, 10 ground truth answers per question
The Street View House Numbers (SVHN)

This is a real-world image dataset for developing object detection algorithms. This requires minimum data preprocessing. It is similar to the MNIST dataset mentioned in this list, but has more labelled data (over 600,000 images). The data has been collected from house numbers viewed in Google Street View.
Size: 2.5 GB
Number of Records: 6,30,420 images in 10 classes
CIFAR-10

This dataset is another one for image classification. It consists of 60,000 images of 10 classes (each class is represented as a row in the above image). In total, there are 50,000 training images and 10,000 test images. The dataset is divided into 6 parts – 5 training batches and 1 test batch. Each batch has 10,000 images.
Size: 170 MB
Number of Records: 60,000 images in 10 classes
SOTA : ShakeDrop regularization
Fashion-MNIST

Fashion-MNIST consists of 60,000 training images and 10,000 test images. It is a MNIST-like fashion product database. The developers believe MNIST has been overused so they created this as a direct replacement for that dataset. Each image is in greyscale and associated with a label from 10 classes.
Size: 30 MB
Number of Records: 70,000 images in 10 classes
Natural Language Processing
IMDB Reviews
This is a dream dataset for movie lovers. It is meant for binary sentiment classification and has far more data than any previous datasets in this field. Apart from the training and test review examples, there is further unlabeled data for use as well. Raw text and preprocessed bag of words formats have also been included.
Size: 80 MB
Number of Records: 25,000 highly polar movie reviews for training, and 25,000 for testing
Twenty Newsgroups
This dataset, as the name suggests, contains information about newsgroups. To curate this dataset, 1000 Usenet articles were taken from 20 different newsgroups. The articles have typical features like subject lines, signatures, and quotes.
Size: 20 MB
Number of Records: 20,000 messages taken from 20 newsgroups
Sentiment140
Sentiment140 is a dataset that can be used for sentiment analysis. A popular dataset, it is perfect to start off your NLP journey. Emotions have been pre-removed from the data. The final dataset has the below 6 features:
- polarity of the tweet
- id of the tweet
- date of the tweet
- the query
- username of the tweeter
- text of the tweet
Size: 80 MB (Compressed)
Number of Records: 1,60,000 tweets
WordNet
Mentioned in the ImageNet dataset above, WordNet is a large database of English synsets. Synsets are groups of synonyms that each describe a different concept. WordNet’s structure makes it a very useful tool for NLP.
Size: 10 MB
Number of Records: 117,000 synsets is linked to other synsets by means of a small number of “conceptual relations.
Yelp Reviews
This is an open dataset released by Yelp for learning purposes. It consists of millions of user reviews, businesses attributes and over 200,000 pictures from multiple metropolitan areas. This is a very commonly used dataset for NLP challenges globally.
Size: 2.66 GB JSON, 2.9 GB SQL and 7.5 GB Photos (all compressed)
Number of Records: 5,200,000 reviews, 174,000 business attributes, 200,000 pictures and 11 metropolitan areas
SOTA : Attentive Convolution
The Wikipedia Corpus
This dataset is a collection of a the full text on Wikipedia. It contains almost 1.9 billion words from more than 4 million articles. What makes this a powerful NLP dataset is that you search by word, phrase or part of a paragraph itself.
Size: 20 MB
Number of Records: 4,400,000 articles containing 1.9 billion words
The Blog Authorship Corpus
This dataset consists of blog posts collected from thousands of bloggers and has been gathered from blogger.com. Each blog is provided as a separate file. Each blog contains a minimum of 200 occurrences of commonly used English words.
Size: 300 MB
Number of Records: 681,288 posts with over 140 million words
Machine Translation of Various Languages
This dataset consists of training data for four European languages. The task here is to improve the current translation methods. You can participate in any of the following language pairs:
- English-Chinese and Chinese-English
- English-Czech and Czech-English
- English-Estonian and Estonian-English
- English-Finnish and Finnish-English
- English-German and German-English
- English-Kazakh and Kazakh-English
- English-Russian and Russian-English
- English-Turkish and Turkish-English
Size: ~15 GB
Number of Records: ~30,000,000 sentences and their translations
SOTA : Attention Is All You Need
Audio/Speech Datasets
Free Spoken Digit Dataset
Another entry in this list for inspired by the MNIST dataset! This one was created to solve the task of identifying spoken digits in audio samples. It’s an open dataset so the hope is that it will keep growing as people keep contributing more samples. Currently, it contains the below characteristics:
- 3 speakers
- 1,500 recordings (50 of each digit per speaker)
- English pronunciations
Size: 10 MB
Number of Records: 1,500 audio samples
Free Music Archive (FMA)
FMA is a dataset for music analysis. The dataset consists of full-length and HQ audio, pre-computed features, and track and user-level metadata. It an an open dataset created for evaluating several tasks in MIR. Below is the list of csv files the dataset has along with what they include:
tracks.csv: per track metadata such as ID, title, artist, genres, tags and play counts, for all 106,574 tracks.genres.csv: all 163 genre IDs with their name and parent (used to infer the genre hierarchy and top-level genres).features.csv: common features extracted with librosa.echonest.csv: audio features provided by Echonest (now Spotify) for a subset of 13,129 tracks.
Size: ~1000 GB
Number of Records: ~100,000 tracks
Ballroom
This dataset contains ballroom dancing audio files. A few characteristic excerpts of many dance styles are provided in real audio format. Below are a few characteristics of the dataset:
- Total number of instances: 698
- Duration: ~30 s
- Total duration: ~20940 s
Size: 14GB (Compressed)
Number of Records: ~700 audio samples
Million Song Dataset

The Million Song Dataset is a freely-available collection of audio features and metadata for a million contemporary popular music tracks. Its purposes are:
- To encourage research on algorithms that scale to commercial sizes
- To provide a reference dataset for evaluating research
- As a shortcut alternative to creating a large dataset with APIs (e.g. The Echo Nest’s)
- To help new researchers get started in the MIR field
The core of the dataset is the feature analysis and metadata for one million songs. The dataset does not include any audio, only the derived features. The sample audio can be fetched from services like7digital, using code provided by Columbia University.
Size: 280 GB
Number of Records: PS – its a million songs!
LibriSpeech
This dataset is a large-scale corpus of around 1000 hours of English speech. The data has been sourced from audiobooks from the LibriVox project. It has been segmented and aligned properly. If you’re looking for a starting point, check out already prepared Acoustic models that are trained on this data set at kaldi-asr.org and language models, suitable for evaluation, at http://www.openslr.org/11/.
Size: ~60 GB
Number of Records: 1000 hours of speech
VoxCeleb
VoxCeleb is a large-scale speaker identification dataset. It contains around 100,000 utterances by 1,251 celebrities, extracted from YouTube videos. The data is mostly gender balanced (males comprise of 55%). The celebrities span a diverse range of accents, professions and age. There is no overlap between the development and test sets. It’s an intriguing use case for isolating and identifying which superstar the voice belongs to.
Size: 150 MB
Number of Records: 100,000 utterances by 1,251 celebrities
Analytics Vidhya Practice Problems
For your practice, we also provide real life problems and datasets to get your hands dirty. In this section, we’ve listed down the deep learning practice problems on our DataHack platform.
Twitter Sentiment Analysis
Hate Speech in the form of racism and sexism has become a nuisance on twitter and it is important to segregate these sort of tweets from the rest. In this Practice problem, we provide Twitter data that has both normal and hate tweets. Your task as a Data Scientist is to identify the tweets which are hate tweets and which are not.
Size: 3 MB
Number of Records: 31,962 tweets
Age Detection of Indian Actors
This is a fascinating challenge for any deep learning enthusiast. The dataset contains thousands of images of Indian actors and your task is to identify their age. All the images are manually selected and cropped from the video frames resulting in a high degree of variability interms of scale, pose, expression, illumination, age, resolution, occlusion, and makeup.
Size: 48 MB (Compressed)
Number of Records: 19,906 images in the training set and 6636 in the test set
Urban Sound Classification
This dataset consists of more than 8000 sound excerpts of urban sounds from 10 classes. This practice problem is meant to introduce you to audio processing in the usual classification scenario.
Size: Training set – 3 GB (Compressed), Test set – 2 GB (Compressed)
Number of Records: 8732 labeled sound excerpts (<=4s) of urban sounds from 10 classes
Subscribe to:
Posts (Atom)